
ディープラーニング実践入門 ~ Kerasライブラリで画像認識をはじめよう!
ディープラーニング(深層学習)に興味あるけど「なかなか時間がなくて」という方のために、コードを動かしながら、さくっと試して感触をつかんでもらえるように、解説します。
はじめまして。宮本優一と申します。
最近なにかと話題の多いディープラーニング(深層学習、deep learning)。エンジニアHubの読者の方でも、興味ある人は多いのではないでしょうか。
しかし、ディープラーニングについて周りのエンジニアに聞いてみると、
「なんか難しそう」
「なかなか時間がなくて、どこから始めれば良いかも分からない」
「一回試してみたんだけど、初心者向けチュートリアル(MNISTなど)を動かして挫折しちゃったんだよね」
という声が聞こえてきます。
そこで! この記事では、そうした方を対象に、ディープラーニングをさくっと試して感触をつかんでもらえるよう、コードを動かしながら解説したいと思います(そのため数式などの厳密な解説は省かせていただきます)。
最後まで試していただけると、自分で用意したデータセットで画像認識ができるようになっているはず! です。
- はじめに ― 私がディープラーニングで開発した「顔認識」システム
- ディープラーニングとは何か?
- ディープラーニングの歴史
- ディープラーニングが使われる分野
- ディープラーニングライブラリ「Keras」を動かしてみよう
- 1. AWSでディープラーニング用のインスタンスを用意する
- 2. KerasでMNISTの手書き数字を認識させてみよう
- 3. Inception v3モデルを用いた画像認識
- まとめと参考文献
はじめに ― 私がディープラーニングで開発した「顔認識」システム
最初に少しだけ自己紹介をさせてください。私は、新卒でデジタルカメラなどを作っている会社に入社し、研究開発部門で画像処理や機械学習のアルゴリズム開発を行ってきました。
5年半ほど勤めた後に転職し、現在はPARTYという会社でリサーチエンジニアとして働いています。PARTYは「最新テクノロジーとストーリーテーリングを融合し、未来の体験をデザインする会社」をスローガンに、さまざまなプロジェクトに取り組んでいます。

そんな私が入社して作ったのが、Deeplooksというサービスです。これは、顔写真をアップロードすると、その顔の「美しさ」を5点満点で点数付けしてくれるというものです(ジョークとして楽しんでいただけると幸いです)。
数万枚の画像に対して人間が点数付けしたデータを、ディープラーニングを用いて学習した結果、「5点の顔」と「2点の顔」の違いをコンピュータが認識して、点数付けできるようになりました。
現在は、このシステムを顔以外にも応用した、新しい認識システムを開発中です。
ディープラーニングとは何か?
最初に、ディープラーニングとはどんなものかを簡単に説明しておきたいと思います。分かっている方は、先の「ディープラーニングライブラリ「Keras」を動かしてみよう」まで読み飛ばしていただいても問題ありません。
AI(人工知能)・機械学習・ディープラーニング(深層学習)の違い
ニュースなどで「人工知能」や「深層学習」といった言葉を聞く機会も増えてきました。しかし、ごちゃまぜに語られることも多く、これらが意味するものの違いが分かりにくいと感じる方もいるかもしれません。
それぞれの言葉の違いについては、これらがどう発展してきたかを解説したNVIDIA社のブログ記事が参考になります。
簡単に説明すると、以下のようになります。
- AI(人工知能、artificial intelligence)
- さまざまなタスクに対して、人間と同等以上の認識精度を持ち、考えることのできる機械
- 機械学習
- データを解析して、特徴を抽出し、データ間の関係を学習する。その結果から、新しいデータに対して予測を行う。決定木、SVMなどさまざまな手法がある
- ディープラーニング
- 機械学習の手法の一つ。ニューラルネットワークを多層に接続し、さまざまな工夫、大量のデータ、高速に計算を実行できるGPUによって、認識性能が向上した
最近は、人間の認識・分類能力をはるかに超えるディープラーニング手法も出てきました。MicrosoftやGoogleのアルゴリズムによる画像認識や、昨年囲碁で世界トップクラスの棋士に勝ったAlphaGoなどは有名なところです。
しかし、これらのアルゴリズムはそれぞれのタスクに最適化されていて、他のタスクを解くことはできないため、真の人工知能を実現したとは言えません。ただ、今までになく人工知能の実現に近づいているといえるでしょう。
ディープラーニングには高機能なGPUが不可欠
機械学習とディープラーニングで大きく異なる点は、開発に必要な環境です。ディープラーニングでは、学習の際にGPUを用いてゴリゴリと計算することが不可欠になっているため、高機能なGPUを備えた環境を準備できるかどうかがネックになります。
さまざまなディープラーニングのライブラリが対応しているのは、NVIDIA社のGPUです。必要なスペックはやりたいタスクに応じて決まるのですが、画像認識であればある程度の高スペックなGPUが要求されます。本稿執筆時点での最低ラインはGeForce GTX 1060で、GeForce GTX 1080 TiかTITAN Xがあれば安心です。
最近では、GPUが利用できるクラウドコンピューティング環境も、Amazon、Google、Microsoft、さくらインターネットなどで提供されているため、かなり試しやすくなっています。本稿でも、Amazonのクラウド環境を利用して、ディープラーニングを試してみます。
ディープラーニングとその他の機械学習手法の使い分けを、環境要因以外で線引きすることは難しいでしょう。タスクによっては、今までの手法の改良で、最新のディープラーニング手法を超えることもあります。
人間が簡単そうに思えるタスクでも機械には難しかったり、逆に人間は難しいと感じることが意外と機械は簡単にできたりするので、知識や経験が豊富な機械学習エンジニアに聞くのが一番だったりします……。
ディープラーニングの歴史
ディープラーニングは、どのように発展したのでしょうか?
ニューラルネットワークとAIブーム
ディープラーニングの元になったのはニューラルネットワーク(neural network)ですが、そのさらに元の元の元となったアルゴリズムである形式ニューロン(formal neuron)は、1943年に発表されました。世界最初のコンピュータといわれるENIACが開発されたのが1946年、人工知能という言葉が生まれたのは1956年と言われていますから、かなり長い歴史があります。
その後、1960年代にかけて第一次AIブームが起きます。しかし、当時の技術では簡単な問題しか解けないことが分かり、1970年代はAIにとって冬の時代が訪れます。
1980年代に入ると、さまざまな知識をもとに最適な答えを導くエキスパートシステムが提案されるなど、再びAI・機械学習ブーム(第二次AIブーム)が起きます。ニューラルネットワークに複数の層を重ねれば、さまざまな表現が可能になり、難しい問題を解けるようになることが分かったのもこの時代です。
例えば、ディープラーニングのライブラリの一つであるTensorFlowのサイトにあるこちらのデモを試していただけると、実感できるかもしれません。FEATURESをx1とx2にして隠れ層(HIDDEN LAYER)を1層にすると単純な分類しかできませんが、
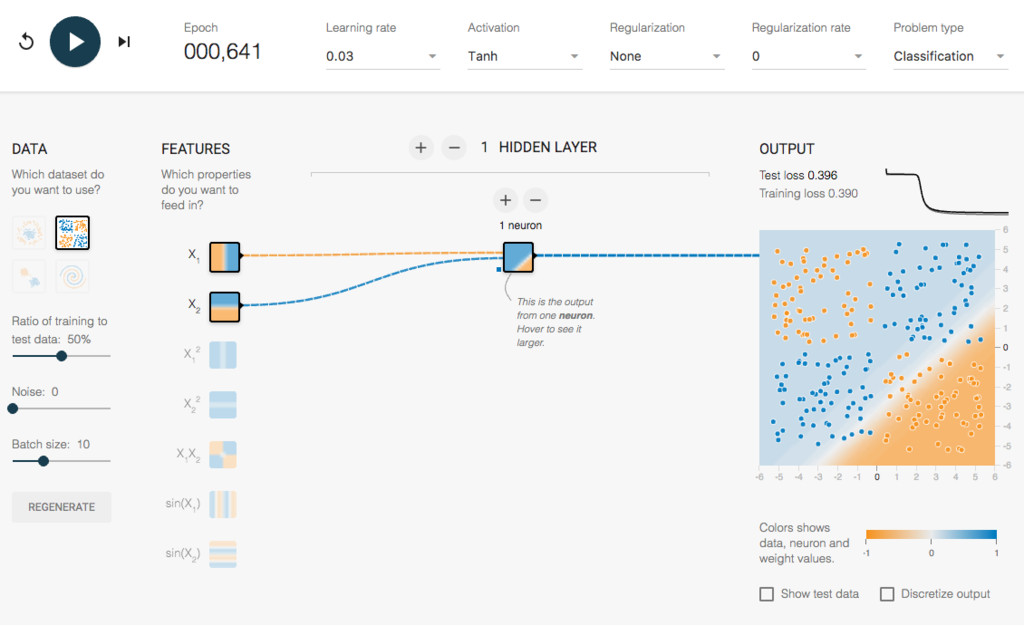
層を複数重ねることによって、複雑な分布をしていても正しく分類できるようになります。
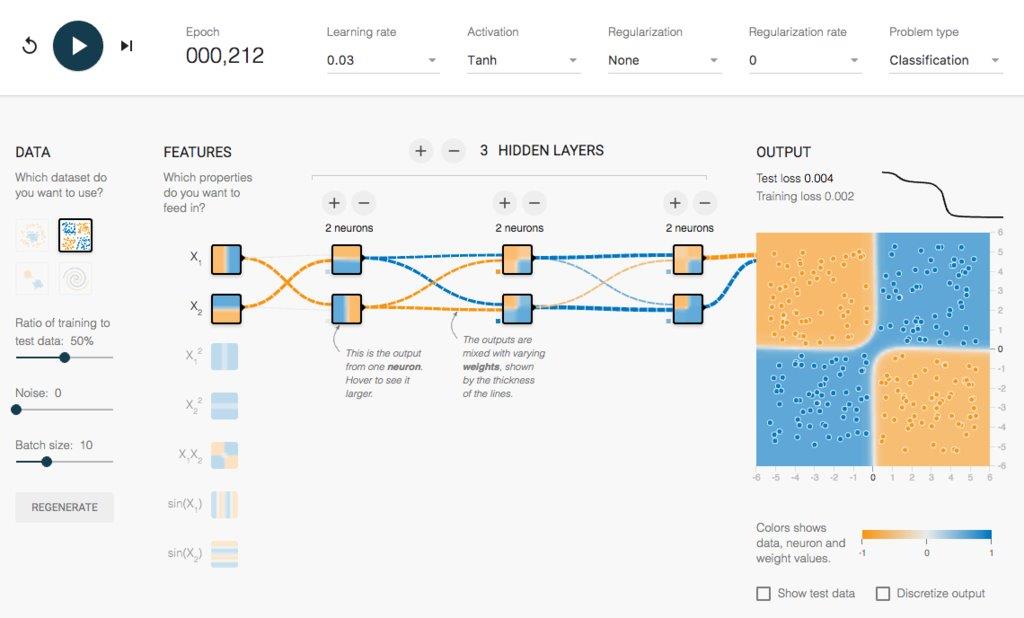
また、このような多層ニューラルネットワークを比較的簡単に最適化できるアルゴリズムも提案されました。
しかし、なかなか上手くいかないのが機械学習です。ニューラルネットワークの層を深くしていけば、より難しい問題が解けるようになる? と思いきや、学習が上手くいかず、なかなか精度を上げることができないという問題にぶち当たります。
機械学習の分野も、1990年代には再び冬の時代が訪れてしまいます。
2000年代に画像認識でブレイク
その後、インターネットの発達で大量のデータを集めやすくなり、コンピュータの処理速度も大幅に向上。機械学習が、社会で徐々に使われるようになってきました。一番身近な例では、デジカメの顔検出などです。この流れが現在まで続いており、ディープラーニングの登場によってかつてないほどのブーム(第三次AIブーム)になっています。
意外かもしれませんが、ニューラルネットワークは、最近までほとんど注目されていませんでした。それどころか、論文中に「ニューラルネットワーク」という言葉が増えるほど採択率が低いとまで言われていました。しかし、逆風の中でも地道に研究が続けられ、2006年には後の成功につながった大きなブレイクスルーもありました。
従来は、形や色など物体を表現する特徴を画像からどう抽出するかを人間がいろいろ試して、そのデータをうまく分割するためのアルゴリズムを調整して適応するということが、一般的な解決法でした。しかし、ディープラーニングの登場によって、特徴抽出から分類まで機械が自動的に計算してくれるようになりました。
ニューラルネットワークが大きく注目されるきっかけになったのは、2012年に開催された「ILSVRC2012」という一般画像認識のコンペティションでしょう。1,000種類の物体(ピアノ、ダルメシアン、雄鶏など)が写った120万枚の画像が用意され、画像認識率を競いましたが、ディープラーニングが他の手法を圧倒してダントツの1位を獲得しました。
この年には、ラベル付けしていない大量のYouTube動画をGoogleがディープラーニングで学習させたところ、猫や人間の顔に反応するニューロンができたということも大きな話題になりました。
当時、私はまだ前の会社にいて、同僚と「なんだかやばい技術が出てきたぞ」と勉強会を始めたのですが、論文を読んでもまったく聞いたことのない理論が出てきて、理解するのにとても苦労しました。今では分かりやすく解説された書籍など、さまざまな教材が出ていて良い時代になったなーと感じます。
ディープラーニングのライブラリも充実してきました。最初は、上記のコンペで1位を獲得した研究者が公開し、ゴリゴリのC++で書かれたcuda-convnetと呼ばれるものくらいしかなかったのですが、今ではTensorFlowやChainer、この記事で解説するKerasなど、使いやすいフレームワークが出てきています。
ディープラーニングが使われる分野
現在、ディープラーニングが実社会で数多く使われている分野は、音声認識や画像認識です。研究分野では、ここ1年くらいで画像生成、強化学習、マルチモーダル学習の分野で大きな成果が出てきています。
例をいくつか見ていきましょう。
音声認識や画像認識
- 音声認識
- スマートフォンの音声入力などで利用されています。
- 画像認識
- フォトアルバムの分類機能や、肺のレントゲン画像からガンの領域を見つける、動画から大量の人のポーズを認識してくれる(下記参照)などがあります。
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
画像生成
指定した画像をデータから生成します。下の例では、どんな鳥かを文章で入力すると、それに近い鳥の画像を生成してくれます。

マルチモーダル学習
ディープラーニングは、異なるモード間の対応が必要な問題(画像と言語、音声と画像など)に強みがあります。例えば、次の技術では「無音声の動画から写っているものを解析して、音を生成」しています。
ディープラーニングライブラリ「Keras」を動かしてみよう
簡単な説明はここまでとして、実際に手を動かしながら、ディープラーニングを学んでいきたいと思います。
本稿では、Pythonで実装されているKerasというライブラリを使い、以下の流れで解説していきます。
Kerasとは? TensorFlowとの関係
ディープラーニングの有名なライブラリとして、先ほどから名前が出ていますが、Googleが開発しているTensorFlowがあります。Kerasは、このTensorFlowと、カナダのモントリオール大学が開発しているTheanoを裏で読み込んでいて、2つのライブラリを切り替えて使うことができます。
日本では最近やっと知名度が上がってきたかなという印象ですが、海外ではかなり使われています。Kerasの作者であるFrançois Chollet(フランソワ・ショレ)によると、GitHubで集計したポピュラリティでTensorFlowが1位、Kerasは3位だそうです(2位のCaffeは初期に出てきたライブラリで、有名ではあるのですが使いにくいです……)。
先日(2017年2月)、TensorFlowが1.0にバージョンアップした際には、TensorFlowからKerasを読み込めるようになるという発表があり、今後は公式にTensorFlowにサポートされます。
程よいバランスで人気が出たKerasの特徴
Kerasのようなライブラリがなぜ生まれ、多くの人に使われるようになったのでしょうか?
TensorFlowもTheanoも、細かいことができる反面、記述が煩雑になっています。ガチガチの研究者であればその方が良いのですが、個人で試すにはオーバースペックという場合も多いのです。
そのため、TensorFlowにはラッパーが何種類か存在するのですが、逆にブラックボックス化されすぎて、やりたいことができなかったりすることもあります。
その中で、Kerasは程よいバランスで使うことができるため、人気が出ました。
他にも、日本語のドキュメントがあったり、話題になった多くのアルゴリズムがKerasで実装されて公開されていたりすることも、おすすめできる理由です。
ただ、一つだけ注意点があります。Kerasは先日(2017年3月)、2.0にアップデートしたのですが、TensorFlowの公式サポートが入ったこともあり、大幅な変更がありました。いくつかの関数が廃止されたり、名前が変わったりしたため、特にバージョン1以前のコードを使う場合には、ワーニングやエラーが出る可能性があります。
1. AWSでディープラーニング用のインスタンスを用意する
ディープラーニングの学習(training)には、GPUが欠かせません。
性能比にもよりますが、CPUだけで学習しようとすると、数倍から数十倍の時間がかかることもあります。GPUを利用しても5日ほどかかる処理を実行しようとするなら、CPUのみでは数ヶ月を費やしてしまうことになるため、非現実的です。
したがって、GPUを搭載したPCを用意するか、Amazon Web Services(AWS)やGoogle Cloud Platform(GCP)といったクラウドコンピューティング環境を利用して、演算する必要があります。
今回は、Amazon EC2でGPUコンピューティングアプリケーション用に用意されたP2インスタンスを用いて、マシンスペックを気にせず手軽に試したいと思います。
この記事の内容を試すために、P2インスタンスを使うと3時間ほどかかります。従量課金制となっており、1時間あたり0.90ドルです(本稿執筆時点)。ただし、使用後にインスタンスを「削除」するのを忘れないでください。
また、Jupyter Notebooksというエディタを使ってプログラムしていきます。Jupyter Notebooksを使うことによって、自分のPCのブラウザ上でインタラクティブにコードを書くことができます。詳細は後ほど説明します。
AWSのアカウントを作成してコンソールにサインイン
AWSのアカウントを持っていない方は、aws.amazon.comでアカウントを作ります。
コンソールにサインインする際に、リージョンは「米国東部(バージニア北部)」を選択します。アジアパシフィック(東京)リージョンを選ぶと、P2インスタンスが使えなくなってしまうので注意してください。

公式のディープラーニング用AMIでインスタンスを選択
「インスタンスの作成」ボタンをクリックします。
Amazonが提供する、ディープラーニング用のAMI(Amazon Machine Image)を使います。GPU用ソフトウェアと各種のディープラーニングライブラリがインストールされているため、煩雑な作業を省略できます。
EC2インスタンスの起動ウィザードのステップ1「Amazonマシンイメージ(AMI)」で「AWS Marketplace」のタブをクリックし、検索窓に「deep learning ami」と入力します。
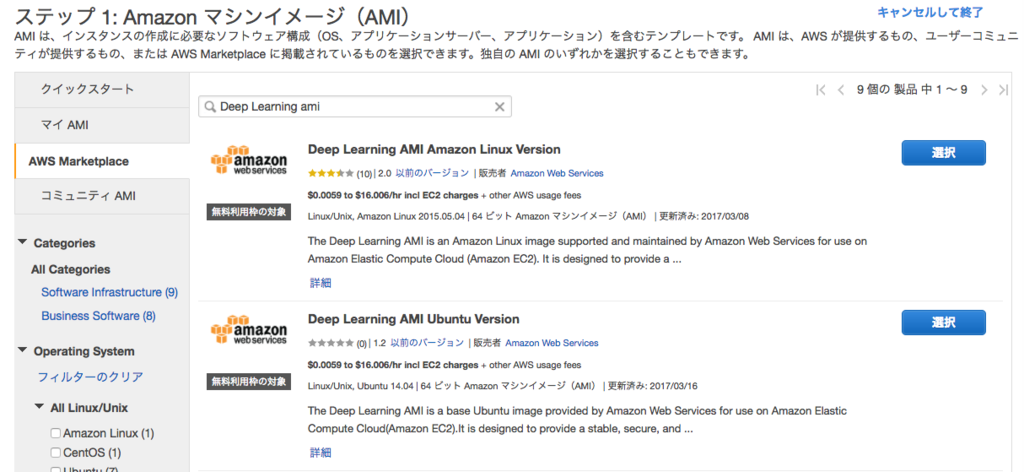
「Deep Learning AMI Ubuntu Version」を見つけて「選択」をクリックします。
ステップ2「インスタンスタイプの選択」では、GPUコンピューティングのp2.xlargeインスタンスを選択します(本稿執筆時点で、NVIDIA Tesla K80というGPUを一つ、1時間あたり0.90ドルで使うことができます)。
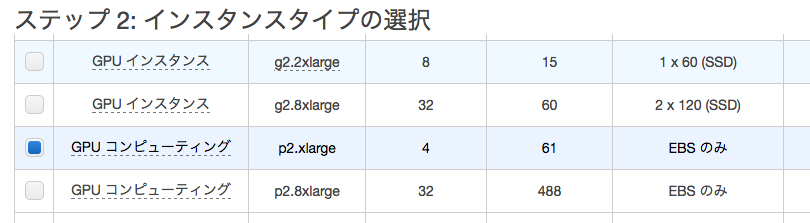
右下の「次の手順」をクリックし、ステップ6の「セキュリティグループの設定」までそのまま進みます。
エディタを使用するセキュリティルールの追加
「セキュリティグループの設定」では、自分のPCブラウザからJupyter Notebookを使うため、次のルールを追加します。
| 項目 | 内容 |
|---|---|
| タイプ | カスタムTCPルール |
| ポート範囲 | 8080 |
| 送信元 | カスタム 0.0.0.0/0 |
「ルールの追加」をクリックして、この内容を入力します。
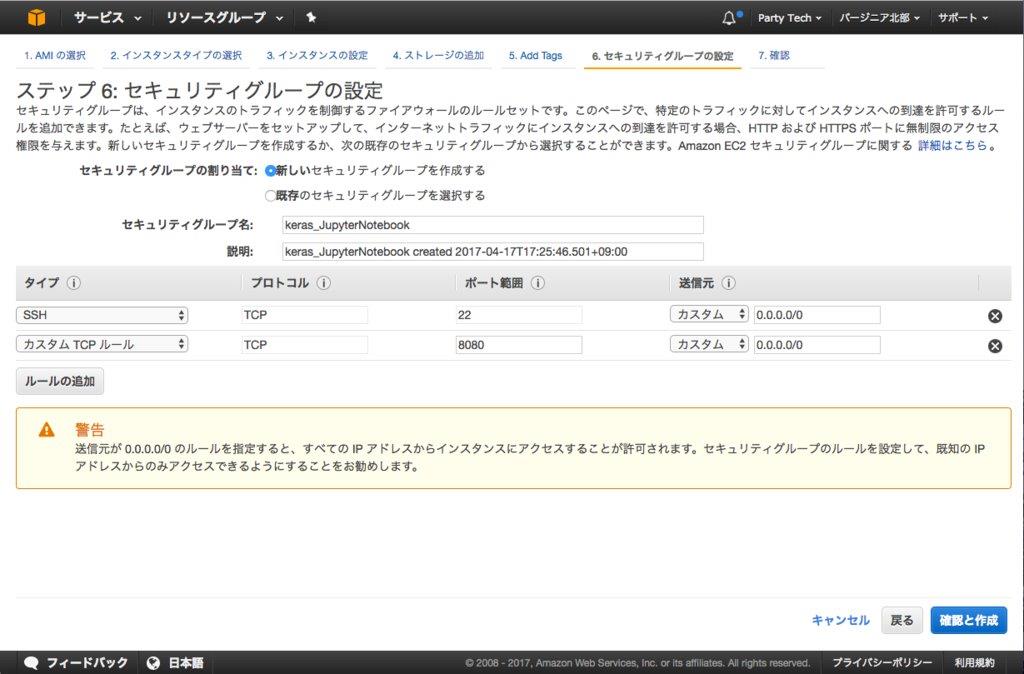
以降の設定でJupyter Notebookにパスワードを登録して無関係な人からのアクセスを制限しますが、もし機密データを取り扱う場合は、送信元として特定のIPアドレスからのアクセスのみを受け入れると良いでしょう。
「確認と作成」をクリックします。
次の画面で「作成」をクリックすると、次のようなポップアップが表示されます。ここで新しい(または既存の)キーペアを設定して「インスタンスの作成」をクリックします。
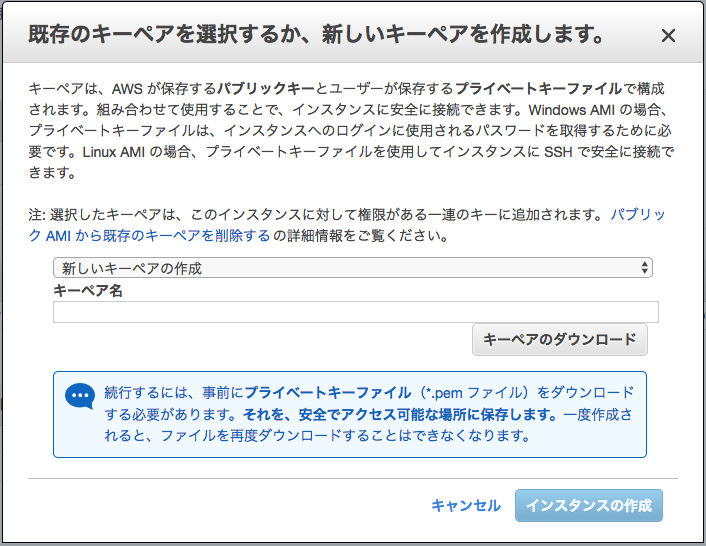
ここで設定したキーペアを使って、インスタンスにSSH経由でログインし、以降の設定を行います。
インスタンスの起動と接続
次のような画面が出たら、インスタンスの起動が始まります。
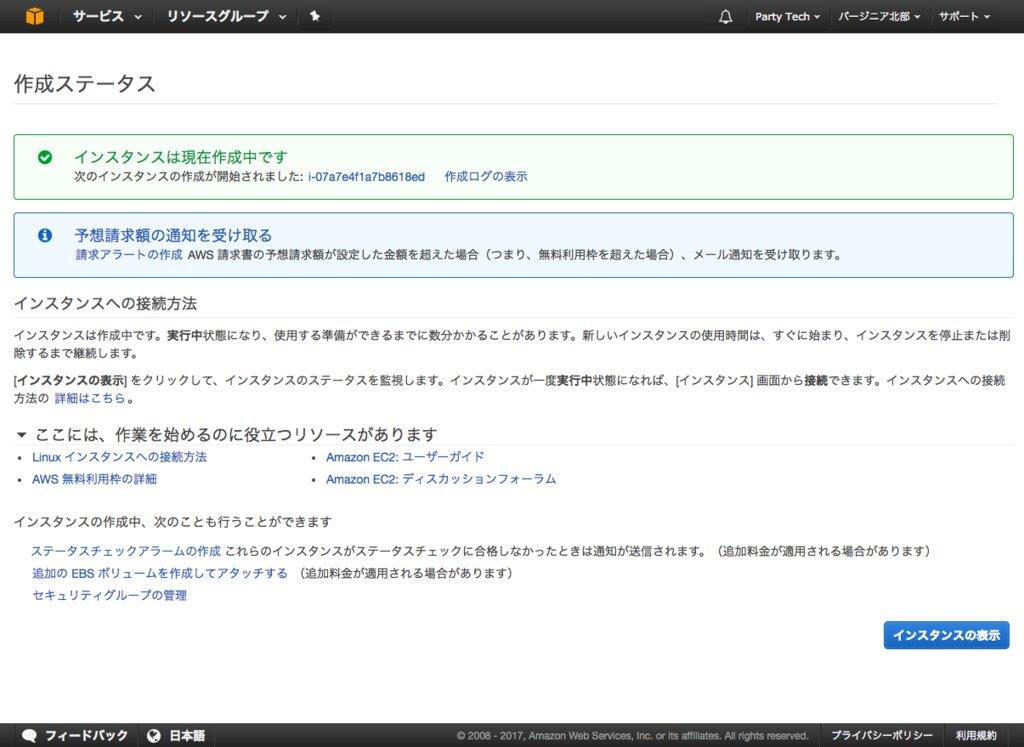
「インスタンスの表示」を押すと、現在起動中のインスタンスの一覧が表示されます。
先ほど起動したインスタンスをチェックし、「接続」をクリックするとこのようなポップアップが出ます。
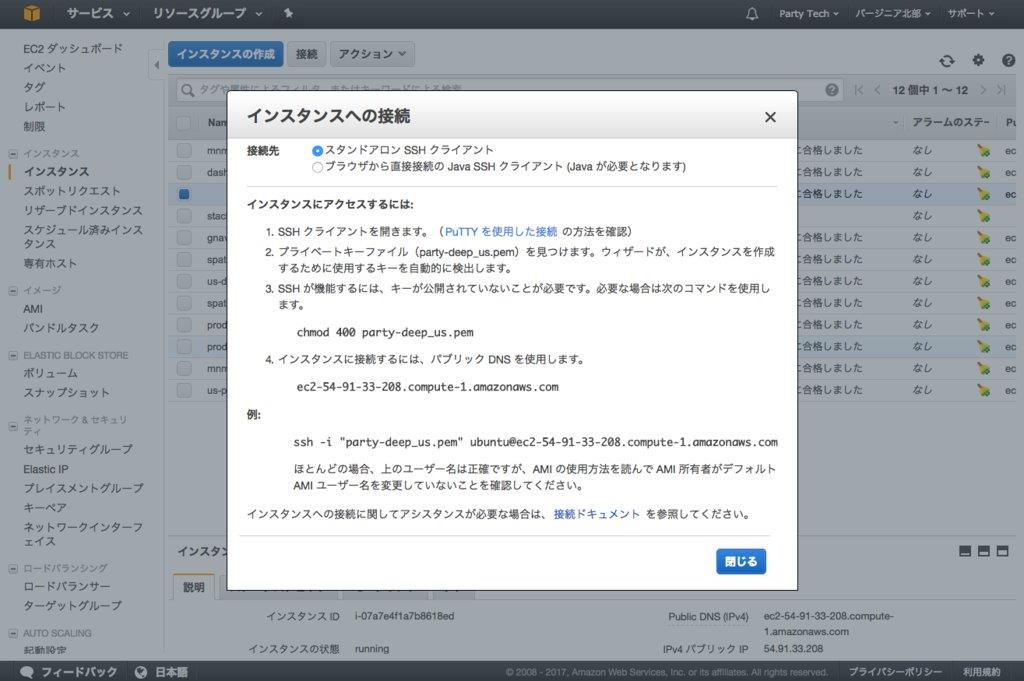
PCでターミナルを起動し、例に従ってコマンドを入力します。
$ ssh -i "[使用するキーファイルの場所と名前].pem" ubuntu@[パブリックDNSのドメイン]
Pythonの動作確認
Deep Learning AMI Ubuntu Versionには、AnacondaというPythonのディストリビューションがインストールされています。
パスが通っていないので、パスを通しておきます。
$ export PATH=/home/ubuntu/src/anaconda3/bin:$PATH
パスを通してPythonを実行すると、以下のように表示されます。
$ python Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 2 2016, 17:53:06)
Kerasのアップデート
ここで使用しているAMIは、Amazonが定期的にアップデートしていますが、タイミングによって最新版がインストールされていないことがあります(本稿執筆時にも最新のバージョン2.0がインストールされていませんでした)。
そのようなときは、手動でアップデートしておきます。
$ sudo chown -R ubuntu src/anaconda3 $ conda install --channel https://conda.anaconda.org/conda-forge keras
Jupyter Notebookの設定と起動
Jupyter Notebookを使う前に、まず設定を行います。
コンフィグファイルを作り、
$ jupyter notebook --generate-config
Jupyterにログインする際のパスワードを設定します。
$ python -c "import IPython; print(IPython.lib.passwd())"
Enter passwordとVerify passwordと出るので、好きなパスワードを入力します。すると、sha1から始まる文字列が表示されます。これは後ほど使いますので、sha1を含めてコピーしておきましょう。
次に、vi(もしくは好きなテキストエディタ)で、先ほど作成したコンフィグファイルを修正します。
$ vi ~/.jupyter/jupyter_notebook_config.py
ファイルを開き、適当なところに以下を入力し、保存します。
c = get_config() c.NotebookApp.ip = '*' c.NotebookApp.open_browser = False c.NotebookApp.port = 8080 c.NotebookApp.password = 'sha1:hogehoge123abc123' #先ほどコピーしたsha1から始まる文字列
Jupyterの設定が完了したら、以下のコマンドを入力してNotebookを起動します。
$ jupyter notebook
ここで起動したNotebookに、自分のPCのWebブラウザからアクセスします。ブラウザのアドレスバーに「インスタンスのIPアドレスまたはドメイン:8080」と入力します。インスタンスのパブリックIP(パブリックDNS)は、AWSのコンソールで確認できます。

表示されたWebページに、先ほど設定したJupyterのパスワードを入力すると、ログインできます。
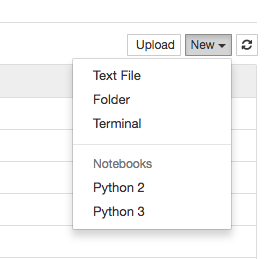
右上の「New」をクリックすると、さまざまなファイルやフォルダを作ることができます。
インスタンスの終了
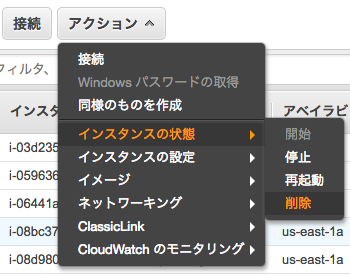
インスタンスの終了方法も説明しておきます。「アクション」からイメージ→イメージの作成を選択すると、このAMIを保存することができ、次回も使うことができます。
AMIを保存したら、アクションからインスタンスの状態→削除を選択し、インスタンスを「削除」して終了です。「削除」をしないと料金がずっと請求され続けるので、必ずちゃんと削除できたか確認しましょう。
2. KerasでMNISTの手書き数字を認識させてみよう
Kerasでは、ディープラーニングのアーキテクチャを表現するモデルの書き方として、Sequentialモデルと、より複雑なアーキテクチャのためにfunctional APIを利用したモデルの2種類があります。
コードを動かす前に、それぞれを簡単に見てみましょう。
KerasのSequentialモデル
まず、Sequentialモデルです。何をやっているかは次章で解説しますが、入力784次元、隠れ層が2つ、出力に10クラス分類をするアーキテクチャです。
from keras.models import Sequential from keras.layers import Dense, Activation import numpy as np #ダミーデータ data = np.random.random((1000, 784)) labels = np.random.randint(10, size=(1000, 1)) labels = to_categorical(labels, 10)#ラベルの変換 model = Sequential() model.add(Dense(64, activation='relu', input_dim=784)) model.add(Dense(64, activation='relu') model.add(Dense(10, activation='softmax')) #モデルのコンパイル model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) #学習を行う model.fit(data, labels)
addを使って、定義した層を一つずつ加えていきます。
functional APIを使ったモデルの書き方
同じモデルをfunctional APIを使って書くと、以下のようになります。最初と最後は同じで、中ほどにあるアーキテクチャを定義するところだけ違っています。
from keras.layers import Input, Dense from keras.models import Model import numpy as np #ダミーデータ data = np.random.random((1000, 784)) labels = np.random.randint(10, size=(1000, 1)) labels = to_categorical(labels, 10)#ラベルの変換 inputs = Input(shape=(784,)) x = Dense(64, activation='relu')(inputs) x = Dense(64, activation='relu')(x) predictions = Dense(10, activation='softmax')(x) #Modelを定義して入力と出力を接続します model = Model(inputs=inputs, outputs=predictions) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(data, labels)
それぞれ、Sequentialモデルは層を積み上げていくイメージで、functional APIは層の出力をロープのようにつなげていくイメージでしょうか。
MNISTデータを読み込む
それでは、いよいよ実際にコードを動かしていきましょう。まず、MNISTデータを読み込みます。
- MNISTデータ
- アメリカ国立標準技術研究所(NIST)が用意した手書き数字の画像データベースで、機械学習の分野で画像認識の入門用サンプルとして利用されている。
前節の「Jupyter Notebookの設定と起動」で解説したように、Jupyter Notebookを起動してブラウザからアクセスします。
適当なフォルダを作り、「New」をクリックして「Python 3」を選択すると、Notebook用の.ipynbファイルが作られます。
以下のコードをセルにコピペして、Runボタンをクリックするか、Shift+Enterを入力してください。
%matplotlib inline import keras from keras.datasets import mnist import matplotlib.pyplot as plt #Kerasの関数でデータの読み込み。データをシャッフルして学習データと訓練データに分割してくれる (x_train, y_train), (x_test, y_test) = mnist.load_data() #MNISTデータの表示 fig = plt.figure(figsize=(9, 9)) fig.subplots_adjust(left=0, right=1, bottom=0, top=0.5, hspace=0.05, wspace=0.05) for i in range(81): ax = fig.add_subplot(9, 9, i + 1, xticks=[], yticks=[]) ax.imshow(x_train[i].reshape((28, 28)), cmap='gray')
コードの実行中は、セルの実行番号が「*」になっているので、処理が終わるまで待ちます。
コードが実行されるとMNISTデータが表示されます。0から9までの手書き数字が画像になっています。
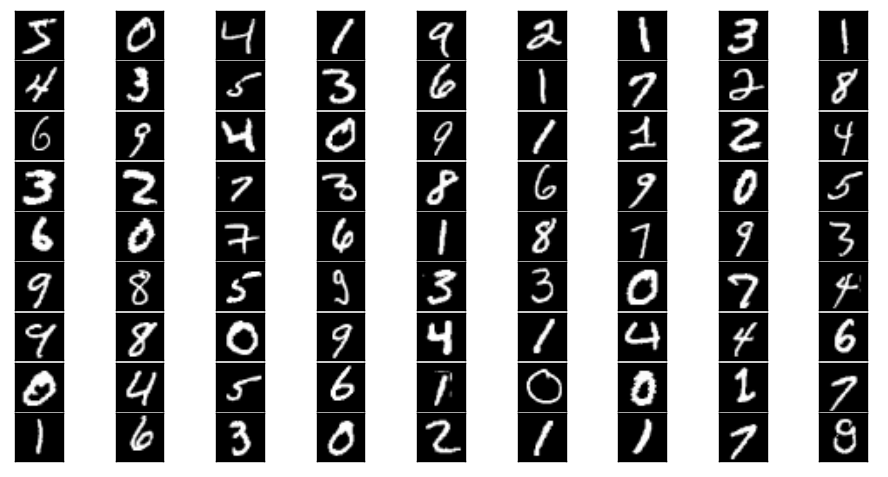
このようにJupyter Notebookでは、処理の途中などで簡単に画像を表示できるので、リモートで処理を行う際にも便利です(matplotlibというライブラリを使って、画像やグラフを表示することができます)。
どの画像がどの数字かを認識するプログラム
これを使って、どの画像がどの数字かを認識するプログラムを書いていきます。
まず、機械が計算しやすい形に、データを変換します。「+」ボタンをクリックし、表示されたセルに以下をコピペして、実行してください。
num_classes = 10 x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 y_train = y_train.astype('int32') y_test = y_test.astype('int32') y_train = keras.utils.np_utils.to_categorical(y_train, num_classes) y_test = keras.utils.np_utils.to_categorical(y_test, num_classes) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples')
reshapeは、28×28画素の画像を784×1のデータに変換しています。
to_categoricalという処理は、y_trainに入っている1、4、2、6などの数字のラベルを、次のように変換しています(one-hotと言います)。
0→[1,0,0,0,0,0,0,0,0,0] 1→[0,1,0,0,0,0,0,0,0,0] 2→[0,0,1,0,0,0,0,0,0,0] 3→[0,0,0,1,0,0,0,0,0,0] …
次にいよいよモデルを定義します。Sequentialモデルを使います。
from keras.models import Sequential from keras.layers import Dense, Dropout, Activation from keras.optimizers import RMSprop model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(10, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
addメソッドで追加しているDenseは、全結合層です。次のような引数を取っています。
| 引数 | 説明 |
|---|---|
512 |
ニューロンの数 |
activation |
活性化関数の指定 |
input_shape |
最初の層では入力の形を指定しなければいけない。それ以降の層では不要 |
Dropoutはディープラーニングの過学習を防ぐために行います。Dropoutは、全結合の層とのつながりをランダムに切断してあげることで、過学習を防ぎます。0.2という数字は、その切断する割合を示しています。
- 過学習
- 学習用のデータに対して適合し過ぎてしまい、その他のデータが入ってきたときにうまく認識できなくなること。「練習問題を一字一句丸暗記してテストに挑んだら、少し違った傾向の問題を出されただけでうまく解けなかった」ときに近い。
compileメソッドでは、学習の際の設定を行います。
| 引数 | 説明 |
|---|---|
loss |
損失関数 |
optimizer |
最適化手法 |
metrics |
評価指標 |
batch_size = 128 epochs = 20 history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
fitメソッドで、学習を行います。epochsの数だけループします。
| 引数 | 説明 |
|---|---|
batch_size |
学習データから設定したサイズごとにデータを取り出し、計算を行う |
epochs |
モデルを学習するエポック数(学習データ全体を何回繰り返し学習させるか)を指定する(バージョン2.0で名前が変更された) |
verbose |
0:標準出力にログを出力しない、1:ログをプログレスバーで標準出力、2:エポックごとに1行のログを出力 |
戻り値をhistoryで受けています。この中にはそれまでの学習の経過が入っているので、matplotlibで表示してみましょう。
#正答率 plt.plot(history.history['acc']) plt.plot(history.history['val_acc']) plt.title('model accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.show() #loss plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.title('model loss') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.show()
20エポックあたりで、testの正答率が上がりきっているのが分かります(lossについてもですが、これらの値は毎回微妙に違います。学習の際にディープラーニングが乱数を使ってさまざまな処理をしているためです)。
学習の履歴を保存する機能があらかじめ用意されているのが、Kerasの便利なところです。
ここで試したモデルは、実は最適なモデルではありません。実際の作業では各種パラメータを操作して、testデータの正答率が最も上がる組み合わせを探していくことになります。
CNNを使って画像を認識する
先ほどは、画像の画素値を、そのまま特徴量として使いました。そのため2次元のデータを1次元に変換したのですが、こう変換してしまうと、上下左右の画素値同士の関係性は考慮されなくなります。
ディープラーニングで画像認識する場合には、一般的にCNN(Convolutional Neural Network、畳み込みニューラルネットワーク)を使います。これにより空間的な特徴を捉えることができます。
新しいファイルを開いて、以下をコピペしてください。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K batch_size = 128 num_classes = 10 epochs = 12 img_rows, img_cols = 28, 28 (x_train, y_train), (x_test, y_test) = mnist.load_data() #Kerasのバックエンドで動くTensorFlowとTheanoでは入力チャンネルの順番が違うので場合分けして書いています if K.image_data_format() == 'channels_first': x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) else: x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') y_train = y_train.astype('int32') y_test = y_test.astype('int32') y_train = keras.utils.np_utils.to_categorical(y_train, num_classes) y_test = keras.utils.np_utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes, activation='softmax')) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
addメソッドで定義しているパラメータが、先ほどとまったく違うのがわかるかと思います。
Conv2Dメソッドでは、kernel_sizeで指定した範囲の画像を見て、畳み込みを行っています。画像における畳み込み計算は、簡単にいうとフィルター処理です(このフィルターは、カーネルとも呼ばれます)。
畳み込み計算は図のように、入力データに対してフィルターを一定の間隔でずらして計算していきます(図の詳細はこちら)。
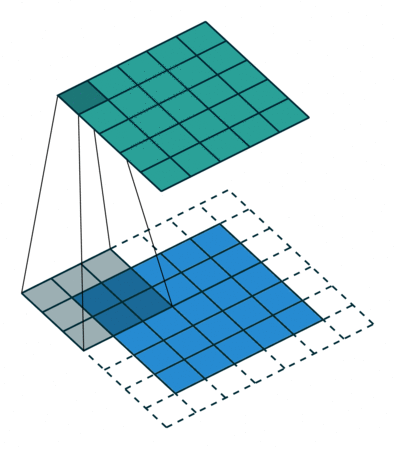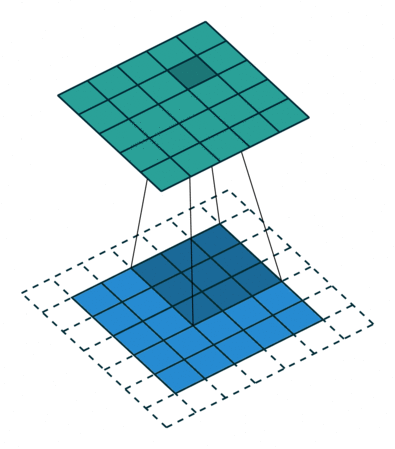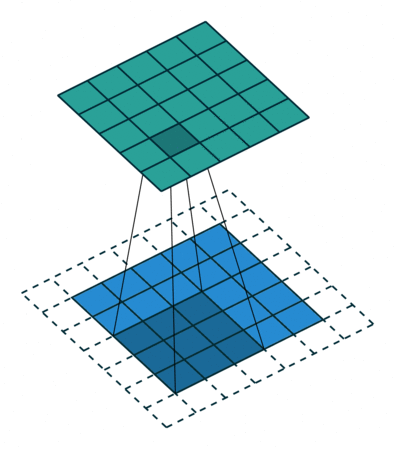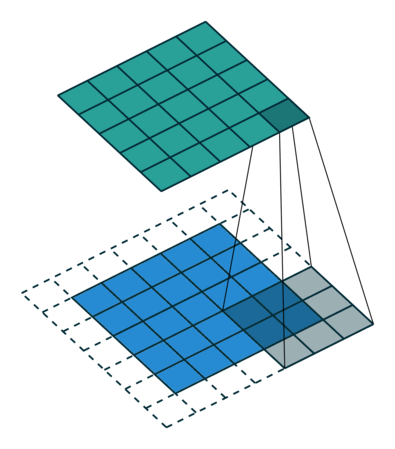
また、MaxPooling2Dメソッドでは、pool_sizeの範囲を見て、その中で最も大きな値を次の層に渡します。これにより、手書きの線が多少ずれていても、同じような特徴を取り出すことができます。
Flattenは、2次元(2D)の特徴を1次元に引き延ばす操作です。
これを実行すると、テストデータでの正答率が99.25%という結果になりました。先ほどのCNNを使わない試行では98.40%だったので、精度が向上しました。
3. Inception v3モデルを用いた画像認識
次は、より本格的に画像認識の問題を扱ってみたいと思います。
データの前処理について
学習を始める前に、認識精度を上げるための前処理について説明します。
ディープラーニングでは、同じ学習データを何回も繰り返し入力することで学習を行いますが、同じ画像を入力し続けると、過学習を起こすことがあります。ニューラルネットワークが画像の特徴を正確に覚えてしまうために起こる現象です。
これを防ぐため、画像を上下左右にずらしたり、回転させたりするなどして、データを微妙に変えながら入力し、実際に用意したデータよりも多様なデータを入力するデータ拡張を行います。
Kerasには、データ拡張のための便利なメソッドが用意されています。
keras.preprocessing.image.ImageDataGenerator(featurewise_center=False, samplewise_center=False, featurewise_std_normalization=False, samplewise_std_normalization=False, zca_whitening=False, rotation_range=0., width_shift_range=0., height_shift_range=0., shear_range=0., zoom_range=0., channel_shift_range=0., fill_mode='nearest', cval=0., horizontal_flip=False, vertical_flip=False, rescale=None, dim_ordering=K.image_dim_ordering())
ImageDataGeneratorメソッドを使うと、さまざまなデータ拡張を、これらのパラメータを変えるだけで行うことができます(やたらと引数が多いのですが、ドキュメントに引数の説明があります)。
また、データの標準化の処理を行うこともできます。
ImageDataGeneratorの後にflowメソッドを使うと、前処理した画像を保存することができます。最初は数枚の画像で試してみて、確認しながらレンジを調整するのが良いでしょう。
学習する際の便利な機能
実験で何回も試行錯誤する上で便利な機能についても、紹介しておきます。
ディープラーニングの学習には、数時間~数日かかるのが一般的です。この学習の途中で、モデルの内部状態や統計情報を表示できる機能が用意されています。
学習する際のfitやfit_generatorメソッドには、callbacksという引数があり、ここに関数を書き込んでおくと、あらかじめ設定した機能を呼び出すことができます。
関数の一例として、次のようなものがあります。
| 関数 | 説明 |
|---|---|
ModelCheckpoint |
各種タイミング(毎エポック終了時や、今まででlossが一番小さかったエポック終了時など)に、学習したモデルを保存できる。保存する名前を、そのエポック数や、lossの値にすることもできる |
EarlyStopping |
lossや正答率が変化しなくなったところで、学習を打ち切ることができる |
LearningRateScheduler |
学習率のスケジューリングができる |
CSVLogger |
各エポックの結果をCSVファイルに保存する |
学習済みモデルの読み込み
Kerasには、いくつかの学習済みのモデルが用意されていて、簡単に読み込むことができます。
- VGG16
- VGG19
- ResNet50
- Inception v3
- CRNN for music tagging
最後の一つは音楽のタグ付けを行うモデルですが、それ以外は画像認識でよく使われているアーキテクチャで、120万枚1,000クラス(imagenetと呼ばれる画像認識で使われるデータセット)の画像認識を行ったモデルです。
このモデルを読み込むことで、自分で数週間かけて学習を行わなくても、1,000クラスの画像認識を動かすことができます。
しかし実際には、自分で用意したデータセットに対して画像を認識させたい場合が多いと思います。このとき、その画像の「仲間」が上記の1,000クラスに入っているような画像の場合(1,000クラスもあるのでたいていのものが含まれると思います)、モデルを再学習することで、少ない画像でも認識精度を高くすることができます。
あらかじめ学習済みのモデルを使って他の学習を行うことを、fine tuning(転移学習)と言います。
今回は「Inception v3」と呼ばれる(名前がかっこいい)モデルを使います。このモデルを図にしたものがこちら。図の四角が各層を表しています。
……はい。なんとなく凄そうということがわかっていただければ、良いかと思います。
このアーキテクチャで1,000クラス分類を行ったところ、予測したトップ5の中に正しい答えがなかった頻度(トップ5エラー率。低いほど良い)は3.46%だったそうです。ちなみに人間(研究者)がやった場合は、5.1%だったそうです。Inception v3やばいですね。
ちなみに「VGG」でのfine tuningに関しては、他のブログなどで解説されていました。Inception v3に関しては、fine tuningの記事があまりなかったので、参考になると思います(ただし、Kerasのバージョンはそれぞれ1.0と1.2)。
fine tuningを使った画像認識
ここで使う画像データは、先ほどのブログを参考に、Kaggleで使われている犬猫画像にします。
Kaggleのページに移動し、Dataタブをクリックして「train.zip」ファイルをダウンロードします。その際に、kaggleにアカウントを登録する必要があります。ここでは、学習データに、犬クラス1,000枚、猫クラス1,000枚、検証用にそれぞれ400枚ずつを使います。
データが用意できたら、スクリプトを書いていきます。
from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input from keras.models import Sequential, Model from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Convolution2D, MaxPooling2D, ZeroPadding2D, GlobalAveragePooling2D, AveragePooling2D from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ModelCheckpoint, CSVLogger, LearningRateScheduler, ReduceLROnPlateau from keras.optimizers import SGD from keras.regularizers import l2 import matplotlib.image as mpimg from scipy.misc import imresize import numpy as np import keras.backend as K import math K.clear_session() img_size=299 #訓練データ拡張 train_datagen = ImageDataGenerator( featurewise_center=False, samplewise_center=False, featurewise_std_normalization=False, samplewise_std_normalization=False, rotation_range=10, width_shift_range=0.2, height_shift_range=0.2, horizontal_flip=True, vertical_flip=False, zoom_range=[.8, 1], channel_shift_range=30, fill_mode='reflect') test_datagen = ImageDataGenerator() #画像の読み込み def load_images(root,nb_img): all_imgs = [] all_classes = [] for i in range(nb_img): img_name = "%s/dog.%d.jpg" % (root, i + 1) img_arr = mpimg.imread(img_name) resize_img_ar = imresize(img_arr, (img_size, img_size)) all_imgs.append(resize_img_ar) all_classes.append(0) for i in range(nb_img): img_name = "%s/cat.%d.jpg" % (root, i + 1) img_arr = mpimg.imread(img_name) resize_img_ar = imresize(img_arr, (img_size, img_size)) all_imgs.append(resize_img_ar) all_classes.append(1) return np.array(all_imgs), np.array(all_classes) X_train, y_train = load_images('./train', 1000) X_test, y_test = load_images('./train', 400) train_generator = train_datagen.flow(X_train, y_train, batch_size=64, seed = 13) test_generator = test_datagen.flow(X_test, y_test, batch_size=64, seed = 13) #Inception v3モデルの読み込み。最終層は読み込まない base_model = InceptionV3(weights='imagenet', include_top=False) #最終層の設定 x = base_model.output x = GlobalAveragePooling2D()(x) predictions = Dense(1, kernel_initializer="glorot_uniform", activation="sigmoid", kernel_regularizer=l2(.0005))(x) model = Model(inputs=base_model.input, outputs=predictions) #base_modelはweightsを更新しない for layer in base_model.layers: layer.trainable = False opt = SGD(lr=.01, momentum=.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) checkpointer = ModelCheckpoint(filepath='model.{epoch:02d}-{val_loss:.2f}.hdf5', verbose=1, save_best_only=True) csv_logger = CSVLogger('model.log') reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=0.001) history = model.fit_generator(train_generator, steps_per_epoch=2000, epochs=10, validation_data=test_generator, validation_steps=800, verbose=1, callbacks=[reduce_lr, csv_logger, checkpointer])
前の章で解説した便利機能も使って書いています。
画像認識の実行結果と精度の確認
これを実行してみると、わずか1エポックで、検証データでの精度が0.99でした。本当はエポックが増えるごとにだんだんlossが下がり、精度が上がっていくところをお見せしたかったのですが、思いのほかInception v3が強力すぎました……。
最初に10エポック指定しましたが、時間がかかってしまうので、モデルが保存されているのを確認したら中断します。
学習したモデルは「model.○○○○.hdf5」という名前で保存されていると思いますので、これを読み込んで精度を確かめてみたいと思います。
from keras.models import load_model import matplotlib.pyplot as plt model = load_model(filepath='./model.00-0.03.hdf5') def predict_img(img_name): img_arr = mpimg.imread(img_name) fig, ax = plt.subplots() ax.imshow(img_arr) plt.show() resize_img = imresize(img_arr, (img_size, img_size)) x=resize_img x = np.expand_dims(x, axis=0) y_pred = model.predict(x) if y_pred <0.5: print (y_pred[0][0], 'dog') else: print (y_pred[0][0], 'cat')
学習に使っていない画像を読み込んでみます。
predict_img('./train/dog.3112.jpg')

predict_img('./train/cat.3011.jpg')

何枚か試しましたが、全部正解でした。恐るべしInception v3……!!
さらにfine tuningする
さて、このモデルからさらにfine tuningしたい場合、例えば、犬猫データを使って学習した後に、10品種のラベルがついたデータが50枚ずつ、合計500枚しかない場合に品種を分類するタスク、などが想定されるでしょうか。
今回の例では最終層しか更新していないので、あまり効果はないと思いますが、似たようなシチュエーションで学習を行ったことがありました。そして微妙にハマりました……。せっかくですので共有します。
最初の学習で、先ほどの例ではmodelを保存していましたが、ModelCheckpointの引数でweightsだけを保存するようにします。
checkpointer = ModelCheckpoint(filepath='model.{epoch:02d}-{val_loss:.2f}.hdf5', verbose=1, save_best_only=True, save_weights_only=True)
fine tuningをします。
#imagenetのmodelは読み込むがweightsは読み込まない base_model = InceptionV3(weights=None, include_top=False) x = base_model.output x = GlobalAveragePooling2D()(x) predictions = Dense(10, init='glorot_uniform', W_regularizer=l2(.0005), activation='softmax', name= '10dogcat')(x)#nameで層に(さっきとは違う)名前をつける model = Model(input=base_model.input, output=predictions) #先ほど学習したweightsを読み込むが、層の名前が違うところは読み込まない model.load_weights("./weight.19-0.70.hdf5", by_name=True)
Kerasでは各層に名前をつけることができるのですが、その名前が保存したweightsの層と違う場合には、by_nameをTrueにすることによって、weightsを読み込まないようにすることができます。
以上で学習は終了です。最後にインスタンスを保存、削除してください。
まとめと参考文献
今回の記事はここまでとなります。かなり駆け足でKerasを使ってみましたが、なんとなくディープラーニングというものがどういうものかイメージしていただけたでしょうか。
記事で解説したのは、ものすごい速度で進歩している技術の一部でしかありませんが、この記事をきっかけにディープラーニングや機械学習に興味を持っていただければ幸いです。
最後に参考になりそうな本やWebページを紹介します。
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
いろんな方がいろんなところで推薦しています。分かりやすさが素晴らしいです。
Bengio先生のおすすめレシピ
実際にディープラーニングを使って学習を進めようとしても、1回でうまくいく可能性は低いです。そこでさまざまなパラメータを調整したり、どこに原因があるのかを探る必要があります。原因を探すコツについて、研究者がまとめたもの(の日本語訳)です。
執筆者プロフィール
宮本優一(みやもと・ゆういち) @miyamotty

2010年、筑波大学大学院修了後、カシオ計算機にて顔認識や高速移動物体追跡など、画像処理・機械学習の研究開発を行う。2015年11月、PARTY入社。入社後は前職での経験を生かし「Deeplooks」の開発、SXSW 2016のSpotifyブースにて展示した「TRUE FAN JUKEBOX」の画像認識システムを手がける。
編集:薄井千春(ZINE)




